

ASTM D6300 Standard Practice for Determination of Precision and Bias Data for Use in Test Methods for Petroleum Products and Lubricants
7. Inspection of Interlaboratory Results for Uniformity and for Outliers
7.1 Introduction:
7.1.1 This section specifies procedures for examining the results reported in a statistically designed interlaboratory program (see Section 6) to establish:
7.1.1.1 The independence or dependence of precision and the level of results;
7.1.1.2 The uniformity of precision from laboratory to laboratory, and to detect the presence of outliers.
NOTE 2 - The procedures are described in mathematical terms based on the notation of Annex A1 and illustrated with reference to the example data (calculation of bromine number) set out in Annex A2. Throughout this section (and Section 8), the procedures to be used are first specified and then illustrated by a worked example using data given in Annex A2.
NOTE 3 - It is assumed throughout this section that all the deviations are either from a single normal distribution or capable of being transformed into such a distribution (see 7.2). Other cases (which are rare) would require different treatment that is beyond the scope of this practice. See (3) for a statistical test of normality.
NOTE 4 - Although the procedures shown here are in a form suitable for hand calculation, it is strongly advised that an electronic computer be used to store and analyze interlaboratory test results, based on the procedures of this practice. The ASTM Committee D-2 Precision Program (4), D2PP, has been designed for this purpose.
7.2 Transformation of Data:
7.2.1 In many test methods the precision depends on the level of the test result, and thus the variability of the reported results is different from sample to sample. The method of analysis outlined in this practice requires that this shall not be so and the position is rectified, if necessary, by a transformation.
7.2.2 The laboratories' standard deviations Dj, and the repeats standard deviations dj (see Annex A1) are calculated and plotted separately against the sample means mj. If the points so plotted may be considered as lying about a pair of lines parallel to the m-axis, then no transformation is necessary. If, however, the plotted points describe non-horizontal straight lines or curves of the form D = f1 (m) and d = f2 (m), then a transformation will be necessary.
7.2.3 The relationships D = f1(m) and d = f2(m) will not in general be identical. The statistical procedures of this practice require, however, that the same transformation be applicable both for repeatability and for reproducibility. For this reason the two relationships are combined into a single dependency relationship D = f(m) (where D now includes d) by including a dummy variable T. This will take account of the difference between the relationships, if one exists, and will provide a means of testing for this difference (see A4.1).
7.2.4 The single relationship D = f(m) is best estimated by weighted linear regression analysis. Strictly speaking, an iteratively weighted regression should be used, but in most cases even an unweighted regression will give a satisfactory approximation. The derivation of weights is described in A4.2, and the computational procedure for the regression analysis is described in A4.3. Typical forms of dependence D = f(m) are given in A3.1. These are all expressed in terms of a single transformation parameter B.
7.2.5 The typical forms of dependence, the transformations they give rise to, and the regressions to be performed in order to estimate the transformation parameters B, are all summarized in A3.2. This includes statistical tests for the significance of the regression (that is, is the relationship D = f(m) parallel to the m-axis), and for the difference between the repeatability and reproducibility relationships, based at the 5 % significance level. If such a difference is found to exist, or if no suitable transformation exists, then the alternative methods of Practice E 691 shall be used. In such an event it will not be possible to test for laboratory bias over all samples (see 7.6) or separately estimate the interaction component of variance (see 8.2).
7.2.6 If it has been shown at the 5 % significance level that there is a significant regression of the form D = f(m), then the appropriate transformation y = F(x), where x is the reported result, is given by the equation
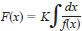
where K = a constant. In that event, all results shall be transformed accordingly and the remainder of the analysis carried out in terms of the transformed results. Typical transformations are given in A3.1.
7.2.7 The choice of transformation is difficult to make the subject of formalized rules. Qualified statistical assistance may be required in particular cases. The presence of outliers may affect judgement as to the type of transformation required, if any (see 7.7).
7.2.8 Worked Example:
7.2.8.1 Table 3 lists the values of m, D, and d for the eight samples in the example given in Annex A2, correct to three significant digits. Corresponding degrees of freedom are in parentheses. Inspection of the values in Table 3 shows that both D and d increase with m, the rate of increase diminishing as m increases. A plot of these figures on log-log paper (that is, a graph of log D and log d against log m) shows that the points may reasonably be considered as lying about two straight lines (see Fig. A4.1 in Annex A4). From the example calculations given in A4.4, the gradients of these lines are shown to be the same, with an estimated value of 0.638. Bearing in mind the errors in this estimated value, the gradient may for convenience be taken as 2/3.
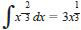
7.2.8.2 Hence, the same transformation is appropriate both for repeatability and reproducibility, and is given by the equation. Since the constant multiplier may be ignored, the transformation thus reduces to that of taking the cube roots of the reported bromine numbers. This yields the transformed data shown in Table A2.2, in which the cube roots are quoted correct to three decimal places.
7.3 Tests for Outliers:
7.3.1 The reported data or, if it has been decided that a transformation is necessary, the transformed results shall be inspected for outliers. These are the values which are so different from the remainder that it can only be concluded that they have arisen from some fault in the application of the test method or from testing a wrong sample. Many possible tests may be used and the associated significance levels varied, but those that are specified in the following subsections have been found to be appropriate in this practice. These outlier tests all assume a normal distribution of errors.
7.3.2 Uniformity of Repeatability - The first outlier test is concerned with detecting a discordant result in a pair of repeat results. This test (5) involves calculating the eij(2) over all the laboratory/sample combinations. Cochran's criterion at the 1 % significance level is then used to test the ratio of the largest of these values over their sum (see A1.5). If its value exceeds the value given in Table A2.3, corresponding to one degree of freedom, n being the number of pairs available for comparison, then the member of the pair farthest from the sample mean shall be rejected and the process repeated, reducing n by 1, until no more rejections are called for. In certain cases, specifically when the number of digits used in reporting results leads to a large number of repeat ties, this test can lead to an unacceptably large proportion of rejections, for example, more than 10 %. If this is so, this rejection test shall be abandoned and some or all of the rejected results shall be retained. A decision based on judgement will be necessary in this case.
7.3.3 Worked Example - In the case of the example given in Annex A2, the absolute differences (ranges) between transformed repeat results, that is, of the pairs of numbers in Table A2.2, in units of the third decimal place, are shown in Table 4. The largest range is 0.078 for Laboratory G on Sample 3. The sum of squares of all the ranges is
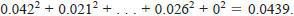
Thus, the ratio to be compared with Cochran's criterion is
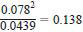
where 0.138 is the result obtained by electronic calculation of unrounded factors in the expression. There are 72 ranges and as, from Table A2.3, the criterion for 80 ranges is 0.1709, this ratio is not significant.
7.3.4 Uniformity of Reproducibility:
7.3.4.1 The following outlier tests are concerned with establishing uniformity in the reproducibility estimate, and are designed to detect either a discordant pair of results from a laboratory on a particular sample or a discordant set of results from a laboratory on all samples. For both purposes, the Hawkins' test (6) is appropriate.
7.3.4.2 This involves forming for each sample, and finally for the overall laboratory averages (see 7.6), the ratio of the largest absolute deviation of laboratory mean from sample (or overall) mean to the square root of certain sums of squares (A1.6).
7.3.4.3 The ratio corresponding to the largest absolute deviation shall be compared with the critical 1 % values given in Table A2.4, where n is the number of laboratory/sample cells in the sample (or the number of overall laboratory means) concerned and where v is the degrees of freedom for the sum of squares which is additional to that corresponding to the sample in question. In the test for laboratory/sample cells v will refer to other samples, but will be zero in the test for overall laboratory averages.
7.3.4.4 If a significant value is encountered for individual samples the corresponding extreme values shall be omitted and the process repeated. If any extreme values are found in the laboratory totals, then all the results from that laboratory shall be rejected.
7.3.4.5 If the test leads to an unacceptably large proportion of rejections, for example, more than 10 %, then this rejection test shall be abandoned and some or all of the rejected results shall be retained. A decision based on judgement will be necessary in this case.
7.3.5 Worked Example:
7.3.5.1 The application of Hawkins' test to cell means within samples is shown below.
7.3.5.2 The first step is to calculate the deviations of cell means from respective sample means over the whole array. These are shown in Table 5, in units of the third decimal place. The sum of squares of the deviations are then calculated for each sample. These are also shown in Table 5 in units of the third decimal place.
7.3.5.3 The cell to be tested is the one with the most extreme deviation. This was obtained by Laboratory D from Sample 1. The appropriate Hawkins' test ratio is therefore:
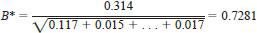
7.3.5.4 The critical value, corresponding to n = 9 cells in sample 1 and v = 56 extra degrees of freedom from the other samples is interpolated from Table A2.4 as 0.3729. The test value is greater than the critical value, and so the results from Laboratory D on Sample 1 are rejected.
7.3.5.5 As there has been a rejection, the mean value, deviations, and sum of squares are recalculated for Sample 1, and the procedure is repeated. The next cell to be tested will be that obtained by Laboratory F from Sample 2. The Hawkins' test ratio for this cell is:
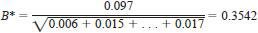
7.3.5.6 The critical value corresponding to n = 9 cells in Sample 2 and v = 55 extra degrees of freedom is interpolated from Table A2.4 as 0.3756. As the test ratio is less than the critical value there will be no further rejections.
7.4 Rejection of Complete Data from a Sample:
7.4.1 The laboratories standard deviation and repeats standard deviation shall be examined for any outlying samples. If a transformation has been carried out or any rejection made, new standard deviations shall be calculated.
7.4.2 If the standard deviation for any sample is excessively large, it shall be examined with a view to rejecting the results from that sample.
7.4.3 Cochran's criterion at the 1 % level can be used when the standard deviations are based on the same number of degrees of freedom. This involves calculating the ratio of the largest of the corresponding sums of squares (laboratories or repeats, as appropriate) to their total (see A1.5). If the ratio exceeds the critical value given in Table A2.3, with n as the number of samples and v the degrees of freedom, then all the results from the sample in question shall be rejected. In such an event care should be taken that the extreme standard deviation is not due to the application of an inappropriate transformation (see 7.1), or undetected outliers.
7.4.4 There is no optimal test when standard deviations are based on different degrees of freedom. However, the ratio of the largest variance to that pooled from the remaining samples follows an F-distribution with v1 and v2 degrees of freedom (see A1.7). Here v1 is the degrees of freedom of the variance in question and v2 is the degrees of freedom from the remaining samples. If the ratio is greater than the critical value given in A2.6, corresponding to a significance level of 0.01/S where S is the number of samples, then results from the sample in question shall be rejected.
7.4.5 Worked Example:
7.4.5.1 The standard deviations of the transformed results, after the rejection of the pair of results by Laboratory D on Sample 1, are given in Table 6 in ascending order of sample mean, correct to three significant digits. Corresponding degrees of freedom are in parentheses.
7.4.5.2 Inspection shows that there is no outlying sample among these. It will be noted that the standard deviations are now independent of the sample means, which was the purpose of transforming the results.
7.4.5.3 The values in Table 7, taken from a test program on bromine numbers over 100, will illustrate the case of a sample rejection.
7.4.5.4 It is clear, by inspection, that the laboratories standard deviation of Sample 93 at 15.76 is far greater than the others. It is noted that the repeats standard deviation in this sample is correspondingly large.
7.4.5.5 Since laboratory degrees of freedom are not the same over all samples, the variance ratio test is used. The variance pooled from all samples, excluding Sample 93, is the sum of the sums of squares divided by the total degrees of freedom, that is
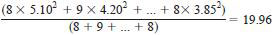
7.4.5.6 The variance ratio is then calculated as where 11.66 is the result obtained by electronic calculation without rounding the factors in the expression.
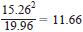
7.4.5.7 From Table A2.8 the critical value corresponding to a significance level of 0.01/8 = 0.00125, on 8 and 63 degrees of freedom, is approximately 4. The test ratio greatly exceeds this and results from Sample 93 shall therefore be rejected.
7.4.5.8 Turning to repeats standard deviations, it is noted that degrees of freedom are identical for each sample and that Cochran's test can therefore be applied. Cochran's criterion will be the ratio of the largest sum of squares (Sample 93) to the sum of all the sums of squares, that is

This is greater than the critical value of 0.352 corresponding to n = 8 and v = 8 (see Table A2.3), and confirms that results from Sample 93 shall be rejected.
7.5 Estimating Missing or Rejected Values:
7.5.1 One of the Two Repeat Values Missing or Rejected - If one of a pair of repeats ( Yij1 or Yij2) is missing or rejected, this shall be considered to have the same value as the other repeat in accordance with the least squares method.
7.5.2 Both Repeat Values Missing or Rejected:
7.5.2.1 If both the repeat values are missing, estimates of aij (= Yij1+Yij2) shall be made by forming the laboratories x samples interaction sum of squares (see Eq 17), including the missing values of the totals of the laboratories/samples pairs of results as unknown variables. Any laboratory or sample from which all the results were rejected shall be ignored and new values of L and S used. The estimates of the missing or rejected values shall be those that minimize the interaction sum of squares.
7.5.2.2 If the value of single pair sum aij has to be estimated, the estimate is given by the equation
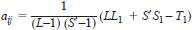
where:
L1 = total of remaining pairs in the ith laboratory,
S1 = total of remaining pairs in the jth sample,
S8 = S - number of samples rejected in 7.4, and
T1 = total of all pairs except aij.
7.5.2.3 If more estimates are to be made, the technique of successive approximation can be used. In this, each pair sum is estimated in turn from Eq 10, using L1, S1, and T1, values, which contain the latest estimates of the other missing pairs. Initial values for estimates can be based on the appropriate sample mean, and the process usually converges to the required level of accuracy within three complete iterations (7).
7.5.3 Worked Example:
7.5.3.1 The two results from Laboratory D on Sample 1 were rejected (see 7.3.4) and thus a 41 has to be estimated.
Total of remaining results in Laboratory 4 = 36.354
Total of remaining results in Sample 1 = 19.845
Total of all the results except a41 = 348.358
Also S8 = 8 and L = 9.
Hence, the estimate of a41 is given by
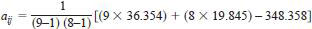
Therefore,
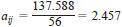
7.6 Rejection Test for Outlying Laboratories:
7.6.1 At this stage, one further rejection test remains to be carried out. This determines whether it is necessary to reject the complete set of results from any particular laboratory. It could not be carried out at an earlier stage, except in the case where no individual results or pairs are missing or rejected. The procedure again consists of Hawkins' test (see 7.3.4), applied to the laboratory averages over all samples, with any estimated results included. If any laboratories are rejected on all samples, new estimates shall be calculated for any remaining missing values (see 7.5).
7.6.2 Worked Example:
7.6.2.1 The procedure on the laboratory averages shown in Table 8 follows exactly that specified in 7.3.4. The deviations of laboratory averages from the overall mean are given in Table 9 in units of the third decimal place, together with the sum of squares. Hawkins' test ratio is therefore:
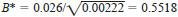
Comparison with the value tabulated in Table A2.4, for n = 9 and v = 0, shows that this ratio is not significant and therefore no complete laboratory rejections are necessary.
7.7 Confirmation of Selected Transformation:
7.7.1 At this stage it is necessary to check that the rejections carried out have not invalidated the transformation used. If necessary, the procedure from 7.2 shall be repeated with the outliers replaced, and if a new transformation is selected, outlier tests shall be reapplied with the replacement values reestimated, based on the new transformation.
7.7.2 Worked Example:
7.7.2.1 It was not considered necessary in this case to repeat the calculations from 7.2 with the outlying pair deleted.